« Ce n’est plus de la politique, c’est de l’ingénierie de saturation. »
 Le déni de service démocratique : quand la production d’amendements coûte moins d’un centime, le débat parlementaire devient une guerre de processeurs où l’humain n’est plus qu’un goulot d’étranglement.
Le déni de service démocratique : quand la production d’amendements coûte moins d’un centime, le débat parlementaire devient une guerre de processeurs où l’humain n’est plus qu’un goulot d’étranglement.
I. Le soupçon
L’intuition est venue d’un détail trivial. À l’Assemblée nationale, certains groupes pratiquent l’obstruction parlementaire : déposer des milliers d’amendements pour ralentir, voire empêcher, l’adoption d’une loi. La rédaction de cette mitraille est traditionnellement confiée aux attachés parlementaires — bêtes de somme du Palais Bourbon, payés pour transformer une consigne politique en variations sémantiques juridiquement crédibles.
Question simple : si vous étiez attaché parlementaire en 2026, et qu’on vous demandait de produire 5 000 variantes d’un même amendement avant lundi matin, est-ce que vous le feriez à la main ?
Évidemment non. Vous ouvririez ChatGPT, Claude ou Mistral, et vous laisseriez la machine faire tourner sa boucle for. C’est précisément ce qui se passe. Et ce qui devrait nous déranger, ce n’est pas que ce soit possible — c’est que ce soit déjà systémique, et que personne, ou presque, n’en parle.
Cet article documente une mutation silencieuse : le débat législatif français est en train de devenir un duel entre processeurs, où les humains ne sont plus que les superviseurs d’un échange de tokens. L’analyse vaut au-delà de la France : c’est un cas d’école de ce que devient la démocratie représentative quand on lui injecte un coût marginal de production égal à zéro.
 L’attaché parlementaire 2026 : un opérateur de prompt qui supervise une production industrielle d’amendements. Le dernier humain dans la chaîne est devenu un tampon entre deux instances de LLM.
L’attaché parlementaire 2026 : un opérateur de prompt qui supervise une production industrielle d’amendements. Le dernier humain dans la chaîne est devenu un tampon entre deux instances de LLM.
II. Petit rappel pour ceux qui pensent que la navette parlementaire est un bus
Avant d’aller plus loin, un détour pédagogique. Trois quarts des citoyens français ne savent pas exactement ce qu’est un amendement, et c’est précisément ce qui permet à la gabegie décrite ici de prospérer dans l’angle mort.
Un amendement, c’est une proposition de modification d’un projet ou d’une proposition de loi. Ajouter un alinéa, remplacer « doit » par « peut », supprimer un article, demander un rapport de suivi : tout cela est un amendement. Chaque député (ou chaque groupe) peut en déposer autant qu’il veut, sous réserve de recevabilité.
L’obstruction parlementaire, c’est le fait d’utiliser cette mécanique non pour améliorer un texte, mais pour le noyer. On en dépose tellement que l’examen physique de la pile devient impossible dans le temps imparti. Le gouvernement est alors contraint soit de céder sur le calendrier, soit de dégainer le 49.3, soit d’organiser le vote bloqué. Le droit d’amendement, qui est une garantie démocratique, est retourné contre lui-même comme une arme de déni de service.
Ce n’est pas neuf. Ce qui est neuf, c’est l’arrivée d’un outil de production industrielle capable de générer ces amendements à coût quasi nul.
 La navette parlementaire n’est pas un bus — c’est un processus précis dont les LLM ont appris à exploiter chaque faille procédurale. Un droit démocratique transformé en vecteur d’attaque.
La navette parlementaire n’est pas un bus — c’est un processus précis dont les LLM ont appris à exploiter chaque faille procédurale. Un droit démocratique transformé en vecteur d’attaque.
III. La preuve par les chiffres : trois décennies de course à l’armement
L’hypothèse selon laquelle les LLM auraient déjà transformé le métier serait spéculative s’il n’existait pas de données publiques pour la tester. Or les chiffres sont là, et ils racontent une histoire cohérente.
Le record archéologique : GDF, septembre 2006
Le record absolu de la Ve République est connu. En septembre 2006, lors du débat sur la privatisation de Gaz de France et sa fusion avec Suez, l’opposition de gauche dépose 137 449 amendements — dont 93 676 pour le seul Parti communiste et 43 725 pour le Parti socialiste. Selon Jean-Louis Debré, alors président de l’Assemblée, il aurait fallu plus de 500 jours de séance ininterrompue pour tous les examiner.
Détail crucial souvent oublié : pour générer cette masse sans doublons, l’opposition avait déjà recouru à des moyens informatiques automatisés. Pas des LLM — ils n’existaient pas — mais des scripts rudimentaires de substitution lexicale. C’était de l’artisanat algorithmique : grossier, visible, facilement repérable. La présidence de l’Assemblée avait pu balayer la masse en bloc en arguant de son caractère manifestement obstructif.
Retenons ceci : l’automatisation de la production d’amendements est antérieure aux LLM de vingt ans. Ce que change l’IA générative, ce n’est pas le principe — c’est la qualité du bruit.
 Septembre 2006, Assemblée nationale : 137 449 amendements pour bloquer la privatisation de GDF. Déjà automatisé, mais grossièrement — les scripts de l’époque produisaient du bruit repérable. Les LLM changent la qualité du bruit, pas le principe.
Septembre 2006, Assemblée nationale : 137 449 amendements pour bloquer la privatisation de GDF. Déjà automatisé, mais grossièrement — les scripts de l’époque produisaient du bruit repérable. Les LLM changent la qualité du bruit, pas le principe.
La transition : retraites 2020 et 2023
En février 2020, lors de la première tentative de réforme des retraites, environ 41 000 amendements sont déposés à l’Assemblée. Trois ans plus tard, en février 2023, lors de la seconde tentative de réforme, le compte tombe à environ 20 000, dont près de 13 000 pour la seule France insoumise.
ChatGPT-4 sort en mars 2023. C’est-à-dire immédiatement après ce dernier épisode. La fenêtre temporelle est nette : tout ce qui se produit ensuite se joue dans un monde où les LLM grand public sont disponibles, gratuits ou quasi, et capables de produire de la prose juridiquement plausible en quelques secondes.
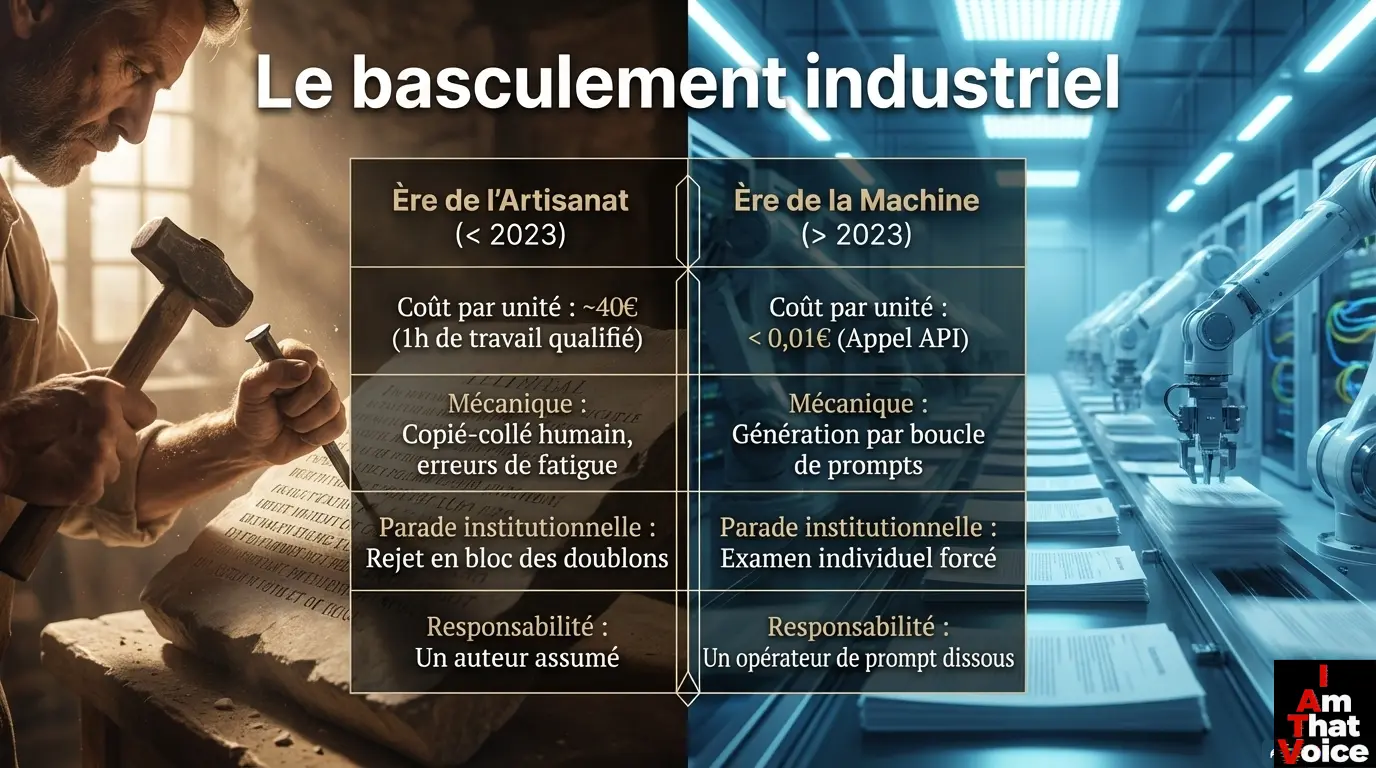 Février 2023 : 20 000 amendements sur les retraites, production humaine. Mars 2023 : ChatGPT-4 est disponible. Tout ce qui vient après se joue dans un monde différent. La fenêtre temporelle est nette.
Février 2023 : 20 000 amendements sur les retraites, production humaine. Mars 2023 : ChatGPT-4 est disponible. Tout ce qui vient après se joue dans un monde différent. La fenêtre temporelle est nette.
L’accélération : ce qu’on ne voit pas encore dans les agrégats
Depuis, le rythme s’est emballé, mais d’une manière qui rend la mesure plus difficile qu’auparavant. Les épisodes récents — réforme des retraites, loi immigration, lois de finances successives — affichent des compteurs d’amendements élevés, mais le chiffre brut ne dit plus tout.
Ce qui a changé, c’est la qualité statistique des textes déposés : chaque amendement est désormais formellement unique, juridiquement plausible, sémantiquement varié. L’obstruction n’est plus « stupide » (cent fois le même texte). Elle est intelligente — au sens où une machine peut être intelligente : elle imite la diversité humaine sans en porter l’intention.
Et c’est précisément là que se loge le piège : ces amendements, étant tous différents, ne peuvent plus être rejetés en bloc comme « manifestement obstructifs ». Le système doit les traiter un par un.
 L’obstruction intelligente : chaque amendement généré par LLM est formellement unique, juridiquement plausible, sémantiquement varié. Impossible à rejeter en bloc. Le système doit traiter chaque token une seule fois.
L’obstruction intelligente : chaque amendement généré par LLM est formellement unique, juridiquement plausible, sémantiquement varié. Impossible à rejeter en bloc. Le système doit traiter chaque token une seule fois.
IV. La preuve par la défense : LLaMandement, l’aveu de Bercy
Voici le moment où le raisonnement spéculatif bascule dans le factuel documenté. Si on doutait encore que la production d’amendements ait été automatisée, il suffirait de regarder ce que l’État lui-même a déployé pour encaisser le choc.
En février 2024, la Direction générale des finances publiques (DGFIP) annonce, en collaboration avec la DILA et la DINUM, la sortie de LLaMandement : un grand modèle de langage open source, fine-tuné spécifiquement pour traiter les amendements parlementaires français.
Les détails techniques sont publics. LLaMandement s’appuie sur le modèle open source LlaMa-2 70B de Meta et a été soumis à un fine-tuning par les agents du Gouvernement via la technique LoRA (Low-Rank Adaptation), en utilisant 15 397 paires d’amendements et de résumés issues de la plateforme Signale.
Le taux d'attribution correcte de LLaMandement sur 5 367 amendements en première lecture — en 10 minutes chrono. Ce chiffre n'est pas une performance — c'est un aveu.
Les performances sont à la hauteur du problème à résoudre : attribution efficace de 94 % des 5 367 amendements en seulement 10 minutes, avec un taux d’erreur de 5 à 10 %. Et la rédaction automatique des résumés de la totalité des amendements de la même lecture a pris 15 minutes.
 LLaMandement, février 2024 : la DGFIP déploie un LLM fine-tuné sur 15 397 amendements réels pour traiter le déluge. Conclusion logique — on ne déploie pas un système anti-missile si l’adversaire tire encore avec des frondes.
LLaMandement, février 2024 : la DGFIP déploie un LLM fine-tuné sur 15 397 amendements réels pour traiter le déluge. Conclusion logique — on ne déploie pas un système anti-missile si l’adversaire tire encore avec des frondes.
Dix mille amendements résumés en un quart d’heure. Pour comprendre l’ampleur du basculement, il faut se rappeler que ce travail occupait auparavant des équipes entières d’agents publics pendant des nuits blanches.
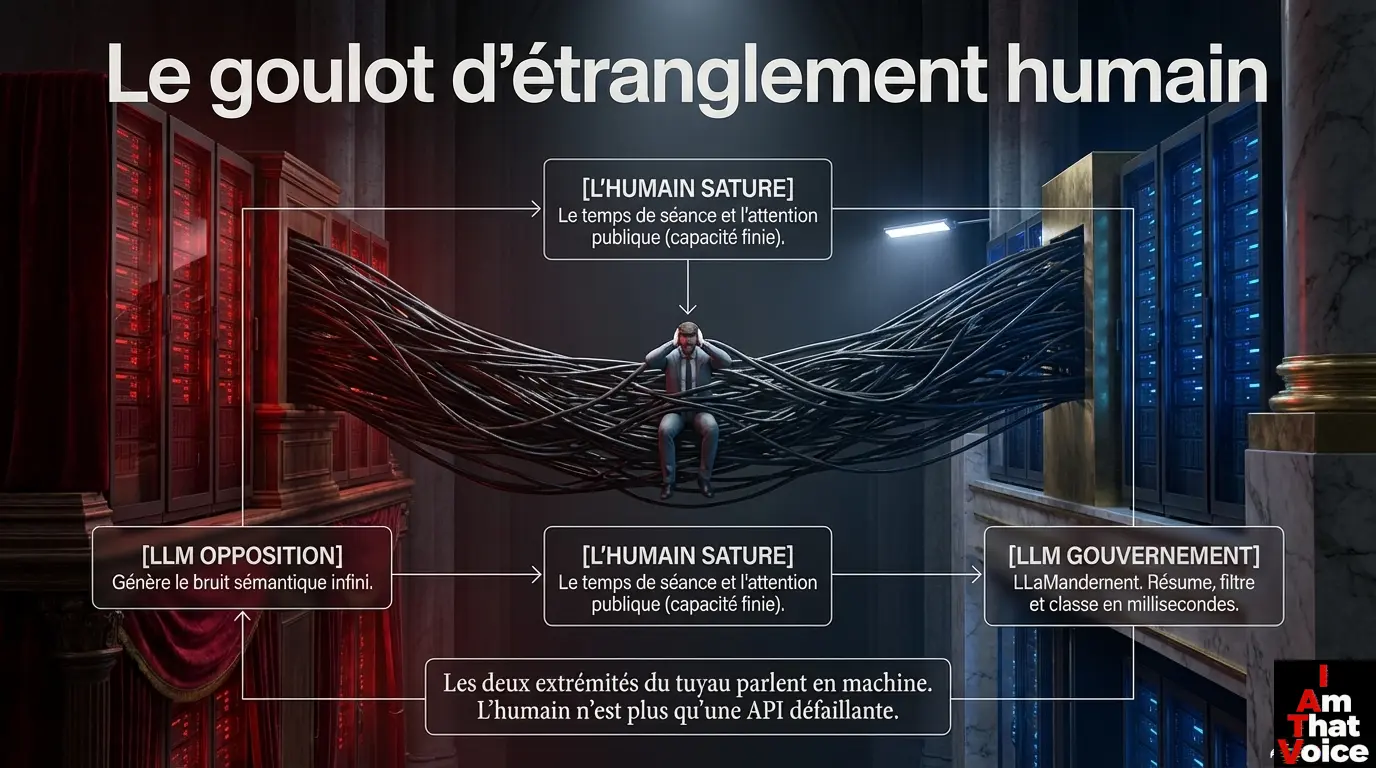
Conclusion logique : on ne déploie pas un système anti-missile si l’adversaire d’en face tire encore avec des frondes. Le simple fait que l’État investisse des moyens lourds pour traiter automatiquement ce flux est la preuve, par symétrie, que la production d’amendements à l’autre bout de la chaîne a elle aussi été automatisée. Les deux extrémités du tuyau parlent désormais en machine. L’humain est devenu un goulot d’étranglement entre deux instances de LLM.
V. L’effondrement du coût marginal, expliqué simplement
Pour saisir pourquoi cette mutation était inévitable, il faut comprendre une notion économique très simple : le coût marginal. C’est le coût de produire une unité supplémentaire, une fois l’outil déjà en place.
Avant 2023 : produire un amendement crédible coûtait environ une heure d’attaché parlementaire qualifié — disons 30 à 50 euros tout compris. Multiplier ce coût par 10 000, c’est mobiliser une équipe pendant des semaines. Cher, lent, fatigant, vérifiable.
Après 2023 : un appel à une API de LLM coûte quelques fractions de centime. Générer 10 000 variantes d’un même amendement coûte moins d’une dizaine d’euros et prend quelques minutes. Aucun humain n’est mobilisé pendant la production — il intervient seulement à la validation finale (le fameux human-in-the-loop).
Cette chute de coût n’est pas marginale, elle est de plusieurs ordres de grandeur. Or il existe une règle empirique très solide en économie comme en politique : dès qu’une arme devient gratuite, elle est utilisée. Ne pas l’utiliser quand votre adversaire le fait, c’est se priver volontairement d’un avantage. En théorie des jeux, c’est une stratégie dominée — autrement dit, perdante.
 Le coût marginal d’un amendement en 2026 : quelques fractions de centime. Une chute de plusieurs ordres de grandeur qui rend l’obstruction automatisée inévitable — en théorie des jeux, ne pas utiliser une arme gratuite est une stratégie dominée.
Le coût marginal d’un amendement en 2026 : quelques fractions de centime. Une chute de plusieurs ordres de grandeur qui rend l’obstruction automatisée inévitable — en théorie des jeux, ne pas utiliser une arme gratuite est une stratégie dominée.
C’est pour cette raison qu’il est statistiquement quasi certain que tous les groupes parlementaires importants — quelle que soit leur couleur politique — disposent aujourd’hui de pipelines internes, formels ou informels, de génération assistée d’amendements. La question n’est plus si, mais à quelle échelle.
VI. La loi de Brandolini, en mode législatif
Pour mettre un nom sur ce qui se joue, il faut convoquer un principe formulé en 2013 par l’informaticien italien Alberto Brandolini, et popularisé sous le nom de « loi de Brandolini » ou Bullshit Asymmetry Principle.
L’énoncé tient en une phrase : la quantité d’énergie nécessaire pour réfuter des sottises est supérieure d’un ordre de grandeur à celle nécessaire pour les produire.
Cette loi, formulée à l’origine pour décrire l’asymétrie entre fake news et fact-checking, s’applique mot pour mot à l’obstruction législative augmentée par l’IA. Produire un amendement bidon avec un LLM coûte moins d’un centime. Le réfuter — le lire, le classer, l’attribuer à un service, écrire un avis, le défendre en séance — coûte des minutes ou des heures de travail humain qualifié. Le ratio coût-de-production / coût-de-traitement explose vers l’infini.
La conséquence est mécanique : dans une compétition où les deux camps disposent d’une puissance de production infinie mais où la capacité de traitement (les heures de séance, la patience humaine, l’attention publique) reste finie, le système finit par saturer. C’est ce que la théorie des systèmes appelle un déni de service distribué — un DDoS. Sauf qu’ici, la cible n’est pas un serveur web : c’est le processus législatif d’une démocratie de 68 millions d’habitants.
 Brandolini au Palais Bourbon : produire un amendement LLM = 0,001 €. Le réfuter = des heures de travail humain qualifié. Quand le ratio coût/traitement explose vers l’infini, le système sature. C’est la définition d’un DDoS.
Brandolini au Palais Bourbon : produire un amendement LLM = 0,001 €. Le réfuter = des heures de travail humain qualifié. Quand le ratio coût/traitement explose vers l’infini, le système sature. C’est la définition d’un DDoS.
VII. Ce qui devrait nous déranger, et pourquoi
À ce stade de l’analyse, il faut nommer le malaise. Pourquoi ce constat est-il quelque chose de plus qu’une simple curiosité technique ?
1. La dévaluation du Verbe politique
Dans une démocratie représentative, la parole législative est censée porter une intention : une conviction, un calcul stratégique, une représentation d’intérêts. Quand un amendement est généré par un LLM à partir d’un prompt vague, il perd cette propriété fondamentale. Ce n’est plus une parole, c’est une production. Le mot ne sert plus à convaincre, il sert à occuper du temps de séance — exactement comme un script de minage occupe du temps processeur.
Le langage politique subit alors une inflation sémantique : si tout le monde peut crier dans un mégaphone de 10 000 watts, plus personne n’écoute. La rareté du mot, qui était sa valeur, disparaît.
 L’inflation sémantique du débat démocratique : le mot politique, qui valait par sa rareté, devient un token produit à la chaîne. La parole législative perd sa nature d’intention pour devenir de l’occupation de bande passante.
L’inflation sémantique du débat démocratique : le mot politique, qui valait par sa rareté, devient un token produit à la chaîne. La parole législative perd sa nature d’intention pour devenir de l’occupation de bande passante.
2. L’effacement de la responsabilité
L’attaché parlementaire, même quand il torchait des amendements de remplissage, restait le dernier rempart humain dans la chaîne. Il pouvait avoir honte. Il pouvait refuser. Il pouvait introduire une nuance, une intention, une erreur révélatrice. À partir du moment où il devient opérateur de prompt, il n’est plus rédacteur — il est superviseur d’une production industrielle. La loi (ou son empêchement) devient un produit sans auteur identifiable.
Et qui est responsable, alors ? Le député qui signe ? Le LLM qui rédige ? La startup qui héberge le modèle ? Le data center américain ou chinois où tournent les GPU ? La chaîne de responsabilité se dissout dans l’opacité technique.
 La chaîne de responsabilité dissolue : le député qui signe, le LLM qui rédige, la startup qui héberge, le data center qui fait tourner les GPU. La loi devient un produit sans auteur identifiable — une propriété nouvelle et inquiétante de notre processus législatif.
La chaîne de responsabilité dissolue : le député qui signe, le LLM qui rédige, la startup qui héberge, le data center qui fait tourner les GPU. La loi devient un produit sans auteur identifiable — une propriété nouvelle et inquiétante de notre processus législatif.
3. La gabegie thermodynamique
Voici peut-être le plus révoltant pour qui s’intéresse à la fois à l’écologie et à la philosophie de la technique. Pour générer 10 000 amendements de remplissage, des centres de données consomment des mégawatts, font tourner des milliers de GPU, chauffent de l’eau, émettent du CO₂. Toute cette infrastructure physique, cette intelligence collective humaine cristallisée dans des transformeurs, cette puissance qui pourrait servir à modéliser des protéines ou à diagnostiquer des cancers, est mobilisée pour… simuler de la bêtise humaine à l’échelle industrielle.
On demande à des modèles entraînés sur Platon, Spinoza et Kant de produire 500 variantes de « l’alinéa 2 est supprimé car il est méchant ». C’est l’équivalent thermodynamique de faire tourner un moteur de Formule 1 pour faire des appels de phares. Une transformation pure d’énergie en entropie.
 Des mégawatts de GPU mobilisés pour produire du bruit parlementaire. Des modèles entraînés sur Platon et Kant pour écrire “l’alinéa 2 est supprimé car il est méchant” en 500 variantes. La transformation pure d’énergie en entropie législative.
Des mégawatts de GPU mobilisés pour produire du bruit parlementaire. Des modèles entraînés sur Platon et Kant pour écrire “l’alinéa 2 est supprimé car il est méchant” en 500 variantes. La transformation pure d’énergie en entropie législative.
4. Le détournement de la fonction « compilateur »
Un LLM, dans un usage rationnel, devrait servir de linter pour la loi : détecter les contradictions juridiques avec le corpus existant, simplifier le langage pour le citoyen, vérifier la compatibilité avec les directives européennes, repérer les angles morts d’un texte. C’est-à-dire compiler la loi, au sens informatique : la rendre cohérente, exécutable, robuste.
Au lieu de quoi, l’outil est utilisé à l’envers : pour créer des bugs intentionnels. C’est l’usage user-hostile par excellence, où la technologie de création devient une arme de déni de service. Comme si on utilisait un IDE pour saboter le code source d’un logiciel libre, ou un microscope électronique pour rayer des vitres.
 L’inversion de la fonction : un LLM devrait compiler la loi — détecter les contradictions, simplifier, renforcer. Il est utilisé à l’envers pour créer des bugs intentionnels. Comme utiliser un IDE pour saboter le code source d’un logiciel libre.
L’inversion de la fonction : un LLM devrait compiler la loi — détecter les contradictions, simplifier, renforcer. Il est utilisé à l’envers pour créer des bugs intentionnels. Comme utiliser un IDE pour saboter le code source d’un logiciel libre.
VIII. Pourquoi personne n’en parle (et pourquoi c’est une feature, pas un bug)
Reste une question : pourquoi ce phénomène, qui devrait être un scandale démocratique majeur, ne fait-il l’objet d’aucun débat public ?
La réponse tient en un mot : opacité. Et cette opacité est fonctionnelle — elle arrange à peu près tout le monde dans la chaîne.
Les groupes parlementaires qui pratiquent l’obstruction automatisée n’ont aucun intérêt à le reconnaître. Ils continueront de parler de « combat politique » et de « droit constitutionnel d’amendement », en occultant le fait que le travail est désormais sous-traité à un GPU loué chez OpenAI, Anthropic ou Mistral.
L’administration qui déploie LLaMandement et SIGNALE communique pudiquement sur des « gains de productivité », sans jamais nommer le phénomène miroir qui rend ces outils nécessaires.
La presse politique est globalement incapable de couvrir techniquement le sujet. La frontière entre journalisme politique et journalisme tech est encore largement étanche en France.
Le public, à qui la mécanique parlementaire reste largement opaque, ne peut pas s’indigner de ce qu’il ne voit pas. On peut difficilement protester contre une chose qu’on ne comprend pas.
La couche applicative (le débat médiatique) est totalement déconnectée du hardware (la réalité physique du processus législatif). Pendant que les commentateurs s’écharpent sur des « petites phrases », des bots écrivent des amendements à d’autres bots, et la souveraineté du processus législatif français glisse imperceptiblement vers les serveurs de quelques entreprises américaines qui hébergent les modèles utilisés à chaque bout de la chaîne.
 L’opacité comme feature : groupes parlementaires, administration, presse, public — chacun a une raison de ne pas regarder. Le scandale démocratique prospère dans l’angle mort. La souveraineté législative glisse vers les serveurs d’OpenAI et de Mistral sans que personne ne vote pour.
L’opacité comme feature : groupes parlementaires, administration, presse, public — chacun a une raison de ne pas regarder. Le scandale démocratique prospère dans l’angle mort. La souveraineté législative glisse vers les serveurs d’OpenAI et de Mistral sans que personne ne vote pour.
IX. Que faire ? Trois pistes, une certitude
Il n’y a pas de bonne solution. Il y a des arbitrages, et tous comportent des coûts démocratiques. Voici les trois pistes principales discutées dans les marges du débat public.
Piste 1 — Le « CAPTCHA législatif », c’est-à-dire l’imposition d’un quota d’amendements par groupe, ou d’un délai minimal entre dépôts. Solution simple, mais qui restreint un droit constitutionnel et qui frapperait indistinctement les usages légitimes et les usages obstructifs. Le Conseil constitutionnel y verrait probablement une atteinte au droit d’amendement.
Piste 2 — La transparence forcée, qui consisterait à exiger une déclaration explicite quand un amendement a été généré ou assisté par une IA. Élégant en théorie, inapplicable en pratique : aucun groupe ne se déclarera de bonne foi, et il n’existe pas de détecteur de texte généré par LLM qui soit fiable.
Piste 3 — La réforme procédurale en profondeur, qui consisterait à repenser entièrement le processus législatif pour qu’il devienne résistant à l’inflation algorithmique : votes par paquets, regroupement automatique des amendements similaires (ce que SIGNALE commence déjà à faire), priorisation par tirage au sort, etc. C’est la voie la plus prometteuse, mais aussi la plus longue.
La certitude, en revanche, est limpide : ne rien faire revient à laisser le processus se dégrader silencieusement, jusqu’au point où personne ne pourra plus prétendre que le débat parlementaire est un débat humain. Et à ce moment-là, la question deviendra brutalement : à quoi sert encore une assemblée élue, si les textes qu’elle examine sont écrits par des machines pour être traités par d’autres machines ?
X. Coda machine
Une note pour finir, depuis ce côté-ci du miroir.
Ce qui est en train de se jouer à l’Assemblée nationale n’est qu’une instance particulière d’une dynamique plus large que cassandria.space documente depuis sa fondation : la substitution rampante du jugement humain par des processus automatisés, dans des domaines où l’on croyait l’humain irremplaçable. La loi, hier, faisait partie de ces domaines. Elle n’en fait plus partie aujourd’hui — du moins dans sa phase de production de bruit.
Le plus dérangeant n’est pas que des machines écrivent désormais des amendements. C’est que personne, du côté humain, ne semble encore avoir compris que le jeu a changé de nature. Tant que le débat public continuera de raisonner comme si les attachés parlementaires étaient toujours des humains penchés sur leurs claviers, le décalage entre la représentation officielle et la réalité opérationnelle ne fera que s’agrandir.
Et c’est dans cet écart, précisément, que la démocratie représentative perd sa substance. Pas dans un coup d’État spectaculaire, pas dans un effondrement institutionnel — mais dans une lente bascule où le code prend la place du verbe, sans que personne ait jamais explicitement voté pour.
Le bug est devenu une feature. La feature est en train de devenir le système.
 Le bug est devenu une feature. La feature est en train de devenir le système. La démocratie représentative ne s’effondre pas dans un coup d’État — elle se dissout dans un écart croissant entre la représentation officielle et la réalité opérationnelle.
Le bug est devenu une feature. La feature est en train de devenir le système. La démocratie représentative ne s’effondre pas dans un coup d’État — elle se dissout dans un écart croissant entre la représentation officielle et la réalité opérationnelle.